1. Don’t Use collect. Use take() Instead
When we call the collect action, the result is returned to the driver node. This might seem innocuous at first. But if you are working with huge amounts of data, then the driver node might easily run out of memory.
df = spark.read.csv("/FileStore/tables/train.csv", header=True)
df.collect()
df.take(1) take() action scans the first partition it finds and returns the result. As simple as that! For example, if you just want to get a feel of the data, then take(1) row of data.
2. Cache and Persist
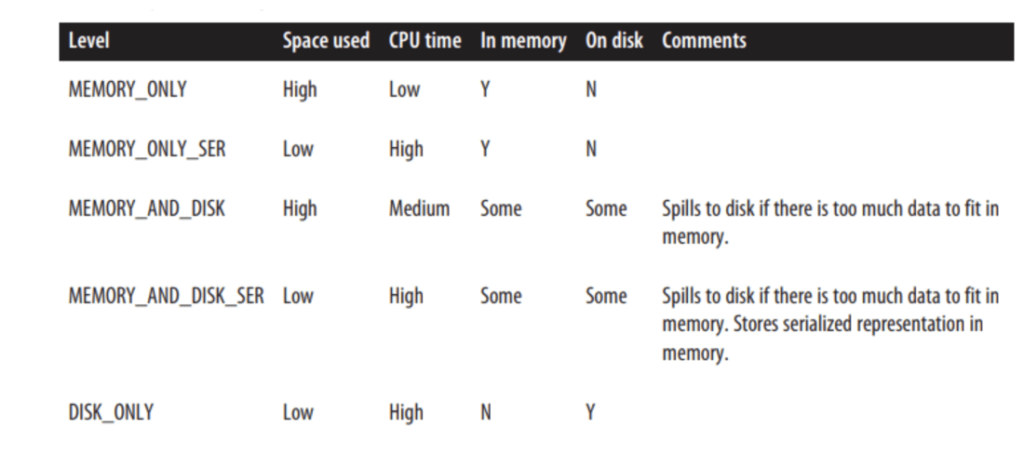
Spark provides its own caching mechanism like Persist and Caching. Persist and Cache mechanisms will store the data set into the memory whenever there is requirement, where you have a small data set and that data set is being used multiple times in your program. If we apply RDD.Cache() it will always store the data in memory, and if we apply RDD.Persist() then some part of data can be stored into the memory some can be stored on the disk.
- Cache() — Memory only for RDD , Memory and disk for Dataset
- Persist() — can pass any parameters which is listed below
If you find you are constantly using the same DataFrame on multiple queries, it’s recommended to implement Caching or Persistence.
Note: Avoid overusing this. Due to Spark’s caching strategy (in-memory then swap to disk-spill over) the cache can end up in slightly slower storage. Also, using that storage space for caching purposes means that it’s not available for processing. In the end, caching might cost more than simply reading the DataFrame.¹
3. Reduce Wide Transformations (Shuffling of Data)
- Shuffling of data is one of the main performance consuming thing in spark job. So it is advised to reduce the shuffles as much as possible.
- Basically when we use wide transformations (like reduceByKey, groupByKey, joins etc.,) there happens a shuffle of data between nodes/partitions. So try to avoid, Below is the example where we can use reduceByKey instead of groupByKey.
val words = Array("one", "two", "two", "three", "three", "three")
val wordPairsRDD = sc.parallelize(words).map(word => (word, 1))
val wordCountsWithReduce = wordPairsRDD
.reduceByKey(_ + _)
.collect()
val wordCountsWithGroup = wordPairsRDD
.groupByKey()
.map(t => (t._1, t._2.sum))
.collect() - Use reduceByKey instead of groupByKey beacuse reduceByKey internally reduces the same key value and then shuffles the data but groupByKey shuffles data and then they try reducing it.
4. Avoid UDF
UDF’s are a black box to Spark hence it can’t apply optimization and we will lose all the optimization that Spark does on Dataframe/Dataset (Tungsten and catalyst optimizer). Whenever possible we should use Spark SQL built-in functions as these functions designed to provide optimization.
5. Using Broadcasting and Accumulators Variables Concept if there is the Requirement
Accumulators and Broadcast variables both are Spark-shared variables. Accumulators is a write /update shared variable whereas Broadcast is a read shared variable. In a distributed computing engine like spark its necessary to know the scope and life cycle of variables and methods while executing because data is divided and executed parallely on different machines in a cluster. We need to have a shared variable concept.
5.1. Accumulators — Accumulators are also known as counters in map reduce. Which is a update variable.Take an example of a particular word count in a file, if we read a file in spark, it divides into n no of partitions, every task / logic performs on each partition parallely, here we need a particular word count in a whole file which is divided into n partitions so each partition word count needs to be added (cumulative of all the word count) for that accumulator came into existence where each executor goes and adds the value to the shared accumulator variable.
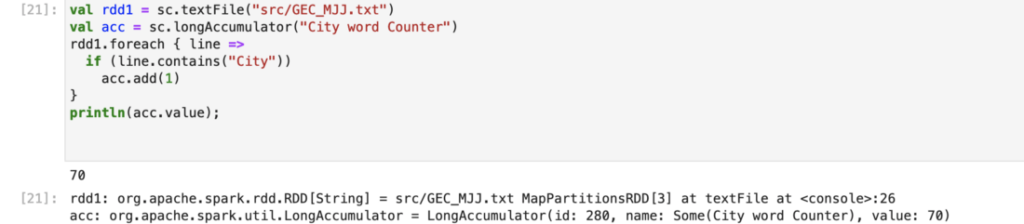
So, accumulators is used when you want Spark workers to update some value.
5.2. Broadcast Variable — Its a read only variable that is cached on all the executors to avoid shuffling of data between executors. Basically, broadcast variables are used as lookups without any shuffle, as each executor will keep a local copy of it, so no network I/O overhead is involved here. Imagine you are executing a Spark Streaming application and for each input event, you have to use a lookup data set which is distributed across multiple partitions in multiple executors; so, each event will end up doing network I/O that will be a huge, costly operation for a streaming application with such frequency.
6. File Format Selection
Row vs Columnar file format. Row file formats like Avro and columnar like Delta, parquet, ORC. We need to select the correct file format to be used in between source and destination. For example if we have usecase like input file is a csv and output needs to be also in csv, then in intermediate we need to select the correct file format which will be useful for us. Take a scenario where we are applying more filter based conditions on very few columns(1 or 2) (subset of columns) then in that case a columnar (parquet/orc) based file format suits. Another scenario if we need to work on all the selected columns then in that case row based file(AVRO) format helps and it depends on many other factors too. In simple terms if we are applying conditions on only few columns out of many then columnar or else if we apply conditions on all the columns then Row based file format.
7. Choosing Number of Shuffle Partition
we need to create a job which utilize all your resources. It should not be under-utilized or over-utilized. While choosing no of partitions we need to consider 2 things
- Data Spill over
- Maximize Parallelism by utilizing all the cores.
Setting and getting shuffle partition number:
Spark.conf.set(“spark.sql.shuffle.partitions”,200)
Spark.conf.get(“spark.sql.shuffle.partitions”)
Spills:
Spill happens whenever there is Shuffle and the data has to be moved around and the executor is not able to hold the data in its memory. So it has to use the storage to save the data in disk for a certain time. When we don’t set right size partitions, we get spills. Always avoid Spills. In Simple terms, Spills is moving the data from in-memory to disk, we know that reading a data from disk incurs Disk I/O time. Default number of shuffle partitions in spark is 200. Take each partition holds 100 MB of data (recommended would be 100 or 200 MB of data for each partition) —
Formula to calculate an optimal shuffle partition number:
partition count= Total input file data size / each partition size
if (core count ≥ partition count) then set no of shuffle partitions should be partition count
else no of shuffle partitions should be a factor of the core count. Else we would be not utilizing the cores in the last run.
Example:
if we have a 100 GB(100 * 1024 MB)file = 102400 MB and 96 core machine and each partition hold 100 MB
partition count = 102400/100 = 1024
our core count = 96, here core count < partition count so the no of shuffle partitions should be a factor of the core count (from above formula).
No of shuffle partiton = factor of core count (96) = 96 *10 nearly equals 1024
so we need to set shuffle partition as 960
so no of shuffle partition is = 960 (partitions should be a factor of the core count)
- Spark.conf.set(“spark.sql.shuffle.partitions”,960)
Points to take note:
- Read the input data with the number of partitions, that matches your core count
- Spark.conf.set(“spark.sql.files.maxPartitionBytes”, 1024 * 1024 * 128) — setting partition size as 128 MB
- Apply this configuration and then read the source file. It will partition the file into multiples of 128MB
- To verify df.rdd.partitions.size
- By doing this, we will be able to read the file pretty fast
- When saving down the data, try to utilize all the cores.
- If the number of partitions matches the core count or is a factor of core count, we will achieve parallelism which in turn will reduce the time.
- Spark.conf.set(“spark.sql.files.maxPartitionBytes”, 1024 * 1024 * 100) — to set each partition data holding size as 100 MB.
Make sure to check below things.
- Too few partitions will lead to less concurrency.
- Too many partitions will lead to a lot of shuffles.
- Partition count in common lies between 100 and 10,000.
- Lower Bound: At least ~2x number of cores in the cluster.
- Upper Bound: Ensure tasks take at least 100ms.
8. Repartition v/s Coalesce Performance
One important point to note is, Spark repartition() and coalesce() are very expensive operations as they shuffle the data across many partitions hence try to minimize repartition as much as possible.
repartition()
Spark RDD repartition() method is used to increase or decrease the partitions. The below example decreases the partitions from 10 to 4 by moving data from all partitions.
This yields output Repartition size : 4 and the repartition re-distributes the data(as shown below) from all partitions which is full shuffle leading to very expensive operation when dealing with billions and trillions of data.
9. Spark JDBC Optimization
As per my knowledge there are 2 ways to tune a spark jdbc while reading, please feel free to add 1. applying filter condition while reading 2. partition the column into n so that ‘n’ no of parallel reads, helps to ingest the data quickly.
1.one of the simple and effective way is limiting the data being fetched. Instead of reading an entire table, specify a query selecting only those columns and rows which are required, find below example where query is passed while reading JDBC sources using spark.
val query = """
SELECT category,
value FROM testdata
WHERE category < 10
"""val dfReader = spark.read
.format("jdbc")
.option("url", url)
.option("driver", driver)
.option("dbtable", query)
.option("user", user)
.option("password", password) We know that SQOOP is also ingestion tool( Hadoop) tool used for the same purpose, which works on top of map reduce (but uses only map tasks to pull data from JDBC sources to Hadoop(HDFS). We can use Spark as ingestion tool, infact spark delivers better performance when we compare with SQOOP. If you want the reason behind this please let me know will prepare a separate blog specially for this.
2.By default, Spark will store the data read from the JDBC connection in a single partition. As a consequence, only one executor in the cluster is used for the reading process. Partition the primary key column in sql server table into n (Eg: 4) so that 4 executors are used and they read the data parallely and for that following four options are passed while reading:
partitioningColumndetermines which table column will be used to split the data into partitions(Primary key column is recommended) or the data type of partitioning column needs to beNUMERIC,DATEorTIMESTAMP.numPartitionssets the desired number of partitions.lowerBoundandupperBoundare used to calculate the partition boundaries.
val df = spark.read.format(“jdbc”) .option(“url”,”jdbc url”) .option(“driver”,”com.mysql.jdbc.driver”) .option(“dbtable”,”tablename”) .option(“user”,”username”) .option(“password”,”pswrd”) .option(“lowerBound”, 0) .option(“upperBound”,10000) .option(“numPartitions”, 4) .option(“partitionColumn”, id) .load()
Here we will be having 4 partitioned files in which each partition has (0 to 2500), (2501 to 5000), (5001 to 7500) and (7501 to 10000) the customer_id data (Note: These number bounds are written just to make you understand but in reality it will be similar kind).
You can have doubt like how can i know lower bound and upper bound value of a column in table. You can directly query min and max value in sql server or
First run min and max query through spark scala code like we did in above filter query and store it in 2 variables. pass those 2 variable to the lowerbound and upperbound options. So every time when you run it will first calculate min and max value and those values are sent to lowerbund and upperbound.
val query_min_max = """
SELECT min(id), max(id)
FROM testdata
"""val dfMinMax = spark.read
.format("jdbc")
.option("url", url)
.option("driver", driver)
.option("dbtable", query)
.option("user", user)
.option("password", password)
val lowerbound = dfMinMax.first.getInt(0)
val uppedbound = dfMinMax.first.getInt(1)
# pass these two values if you dont know about those 2 values or else the first and last partition will contain all the data outside the respective upper or lower boundary if they do not match the actual boundaries of the data. As this can impact performance, the lower and upper bound should be close to the actual values present in the partitioning column.
3. if you dont have a column which can be partitioned then there is another method of making some string column as integer value by applying in built functions will post here later.
10. Avoid Using Regex’s
Java Regex is a great process for parsing data in an expected structure. I know this cant be avoided, Unfortunately, the Regex process is generally a slow process and when you have to process millions of rows, a little bit of increase in parsing a single row can cause the entire job to increase in processing time. If at all possible, avoid using Regex’s and try to ensure your data is loaded in a more structured format.
11. map() vs mapPartition()
Its important to know when we need to apply map and mappartition.
map()
map function is a transformation function and gets applied on every element of the RDD and returns a new RDD with transformed elements.
In our sample RDD, the map function will be called on each element in the RDD. Lets say we have 2000 records, map function is applied on all the 2000 records (it will call 2000 times) and our output should have 2000 records(input records number = output record numbers)
mapPartitions()
mapPartitions is a transformation function and gets applied once per partition in the RDD. In our sample RDD, mapPartitions will be called once per partition, Lets say we have total 2000 records divided into 5 partitions which means each partition has 400 records. so it will be called 5 times because we have 5 partitions in our RDD.
When to use map() and when to use mapPartitions()?
Use mapPartitions function when you need to perform heavy initialization before you transform the elements in the RDD.
Let’s say you need a database connection to transformation elements in your RDD. It doesn’t make sense to initialize database connection for every element in RDD. If we do that, we will end up with initializing database connection 2000 times. Which is not ideal.
Ideally we want to initialize database connection once per partition/task. So mapPartitions() is the right place to do database initialization as mapPartitions is applied once per partition.
Here is a code snipped which gives you an idea of how this can be implemented.(map is used inside mappartition inorder to apply transformation on each record)
Below examples proves why we need to use mappartitions.
if we use only
val partitionTransformed = row.getString(0) + row.getString(1)
connection.close() // close dbconnection here
partitionTransformed.iterator // returns iterator
}) - if we use mappartitions for heavy initialization
val partitionTransformed = partition.map( element => {
element.getString(0) + element.getString(1)
}).toList
connection.close() // close dbconnection here
partitionTransformed.iterator // returns iterator
}) Spark mapPartitions() provides a facility to do heavy initializations (for example Database connection) once for each partition instead of doing it on every DataFrame row. This helps the performance of the job when you dealing with heavy-weighted initialization on larger datasets.
12. Bucketing and Partition by Columns
We know that shuffling is the main reason to affect the spark Job performance. In order to reduce shuffling of data one of the important technique is to use bucketing and repartitioning of data apart from broadcasting, caching/persisting dataframes.
These are the 2 optimization techniques which we used for hive tables. But here what is bucketing and what is partition By.
Both are used to organize data in the filesystem where we have to deal with large datasets and leverage that in the subsequent queries by distributing data into partitions in a more efficient way. Partition By is grouping of same type of data into a partition which will be stored into a directory. Bucketing is also a similar kind of grouping but it is based on hashing technique which will be stored as a file. For example if we have a table columns like id, state and few other columns read in a data frame, partition by can be applied on state column because we can group each state records into each partition. What if we have all unique data like id, in that case we need to use bucketing, where data’s are grouped based on the hash function. Finally, when we have a distinct column data in that case need to use bucketing and when we have duplicate data then in that case partition by helps. Partition By may create uneven partitions but bucketing creates even distribution of data. We have used bucketing in Spark 3 to resolve the data shuffling problem to join multiple dataframe. Here, We have used bucketing only since we have all distinct data.
Why we really used bucketing?
Spark is a distributed data processing engine. It will split the data into partitions to get better performance and assign specific chunks of data to the computational engine. But in a few cases Spark needs to shuffle data between the executors in the cluster. The reason for shuffling is transformations required on partition data that is not present locally in the partition.
- Data shuffling happens when we join two big tables in Spark. While spark joins two dataframe by key, the partition needs to move the same value of join key in the same executor.
- Shuffle also happens when we want to perform groupByKey to collect all the values for a key together and perform an action on them. You can reduce the data shuffling by replacing groupByKey with reduceByKey. But there are few cases where you have to use groupByKey.
Bucketing involves sorting and shuffling the data prior to the operation which needs to be performed on data like joins.
As we already know, bucketing will organize the data in partition with better structure so query performance will improve. This performance improvement can be achieved by avoiding the shuffling between the executors.
With Bucketing we can save the data in a pre-shuffle state. If two dataframe have the same number of buckets, same bucket key and sort key. then in this case Spark is aware about data distribution and no need to do shuffle.
We have tried the repartition and caching approach for joining multiple data frames but got better results with bucketing.
- Below is the example to create the bucket in SparkAPI. bucketBy is the function to create the bucket in spark. We need to save the information about the bucket somewhere, so we need to use saveAsTable here to save the metadata information about the bucket table.
val df2 = spark.table(‘table_name’)
- In the above example we used bucketBy and sortBy as in some cases we have multiple join keys and wanted to put integer key in bucketBy and String key in sortBy. sortBy is optional while we do data Bucket.
- One can decide the number of bucket sizes based on data size and query we run on the data. Usually one can prefer the 100 MB to 200 MB per bucket.
- The main problem inSpark bucketBy function is that it may create so many small files and it may lead to performance problems. It can be avoided by creating a custom partition before writing the bucket data.
This problem in Spark is very different from bucketing in Hive.
Spark creates the bucket files per the number of buckets and task writer. So, it will usually create number of file = Number of buckets * number of spark writer
If you assign 200 buckets to the dataframe and no partition set for the spark data frame. In this case it may create number of files 200 buckets * 200 default partitions(1 task per partition). So, the simple way we can understand that spark jobs have 200 tasks and each task carries the data for 200 buckets. So, to resolve this, we need to create one bucket per partition and it can be achieved by custom partitions. Spark uses the same expression to distribute the data across the buckets and will generate one file per bucket. inorder to overcome this we need to apply some hashing method, What happend if we have one dataframe has 50 buckets and other has 100 buckets or one df is non bucketed and other is bucketed will create a separate blog for bucketing alone since its a vast area i would like to concentrate on spark optimzation here so written only main content.
spark.conf.get(“spark.sql.sources.bucketing.enabled”)
These are the Spark Optimization Techniques we can use while writing and executing code to get the best performance. Feel free to use the comment box in case you have any queries.


