Introduction to PySpark withColumn
PySpark withColumn is a function in PySpark that is basically used to transform the Data Frame with various required values. Transformation can be meant to be something as of changing the values, converting the dataType of the column, or addition of new column. All these operations in PySpark can be done with the use of With Column operation.
The with Column operation works on selected rows or all of the rows column value. This returns a new Data Frame post performing the operation. It is a transformation function that executes only post-action call over PySpark Data Frame.
Syntax for PySpark withColumn:
The syntax for PySpark withColumn function is:
from pyspark.sql.functions import current_date
b.withColumn("New_date", current_date().cast("string"))The PySpark Data Frame:
with column:- The withColumn function to work on.
“New_Date”:- The new column to be introduced.
current_date().cast("string")) :- Expression Needed.Screenshot:
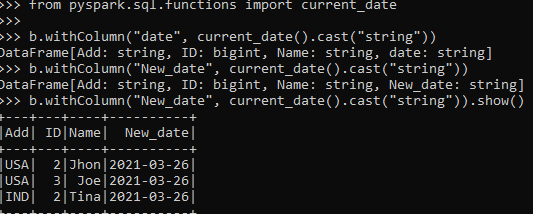
Working of withColumn in PySpark
The With Column function transforms the data and adds up a new column adding. It adds up the new column in the data frame and puts up the updated value from the same data frame. This updated column can be a new column value or an older one with changed instances such as data type or value. It returns a new data frame, the older data frame is retained. It introduces a projection internally. A plan is made which is executed and the required transformation is made over the plan. Operation, like Adding of Columns, Changing the existing value of an existing column, Derivation of a new column from the older one, Changing the Data Type, Adding and update of column, Rename of columns, is done with the help of with column. We can also drop columns with the use of with column and create a new data frame regarding that.
Examples
Let us see some Example how PySpark withColumn function works:
Let’s start by creating simple data in PySpark.
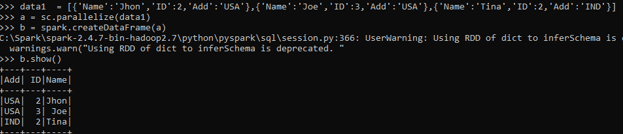
data1 = [{'Name':'Jhon','ID':2,'Add':'USA'},{'Name':'Joe','ID':3,'Add':'USA'},{'Name':'Tina','ID':2,'Add':'IND'}]A sample data is created with Name, ID, and ADD as the field.
a = sc.parallelize(data1)
RDD is created using sc.parallelize.
b = spark.createDataFrame(a)
b.show()Created DataFrame using Spark.createDataFrame.
Screenshot:
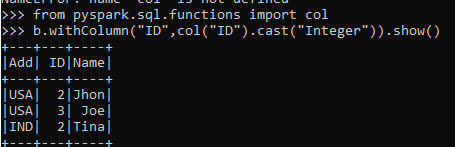
1. Change the Data Type of Existing Column in Data Frame.
Let’s try to change the dataType of a column and use the with column function in PySpark Data Frame.
Code:
from pyspark.sql.functions import col
b.withColumn("ID",col("ID").cast("Integer")).show()Output:
This casts the Column Data Type to Integer.
ScreenShot:
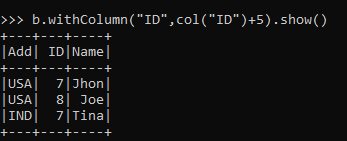
2. Update the Value of an Existing Column of a Data Frame.
Let’s try to update the value of a column and use the with column function in PySpark Data Frame.
Code:
from pyspark.sql.functions import col
b.withColumn("ID",col("ID")+5).show()Output:
This updates the column of a Data Frame and adds value to it.
ScreenShot:
3. Creation of New Column in a Data Frame.
Code:
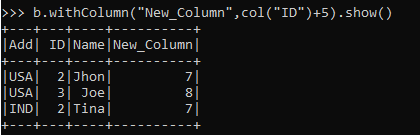
from pyspark.sql.functions import col
b.withColumn("New_Column",col("ID")+5).show()Output:
This create a new column and assigns value to it.
ScreenShot:
4. Addition to a Column in a Data Frame using With Column.
Code:
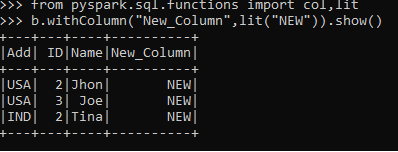
from pyspark.sql.functions import col, lit
b.withColumn("New_Column",lit("NEW")).show()Output:
This adds up a new column with a constant value using the LIT function.
ScreenShot:
5. Adding MULTIPLE columns.
Code:
from pyspark.sql.functions import col
b.withColumn("New_Column",lit("NEW")).withColumn("New_Column2",col("Add")).show()Output:
This add up multiple column in PySpark Data Frame. We can add up multiple columns in a data Frame and can implement values in it.
ScreenShot:

6. Rename an existing column.
The with column renamed function is used to rename an existing function in a Spark Data Frame.
Code:
from pyspark.sql.functions import col
b.withColumnRenamed("Add","Address").show()Output:
This renames a column in the existing Data Frame in PYSPARK.
These are some of the Examples of WITHCOLUMN Function in PySpark.
Note:
1. With Column is used to work over columns in a Data Frame.
2. With Column can be used to create transformation over Data Frame.
3. It is a transformation function.
4. It accepts two parameters. The column name in which we want to work on and the new column.

