PySpark UNION is a transformation in PySpark that is used to merge two or more data frames in a PySpark application. The union operation is applied to spark data frames with the same schema and structure. This is a very important condition for the union operation to be performed in any PySpark application. The union operation can be carried out with two or more PySpark data frames and can be used to combine the data frame to get the defined result. It returns a new Spark Data Frame that contains the union of rows of the data frames used.
Syntax of PySpark Union
The syntax for the PySpark union function is:
Df = df1.union(df2)
Df = DataFrame post union.
Df1 = DataFrame1 used for union operation.
Df2 = DataFrame2 used for union operation.
.union :- The union transformation
c=a.union(b).show()Output:
Working of PySpark Union
Let us see how the UNION function works in PySpark:
- The Union is a transformation in Spark that is used to work with multiple data frames in Spark. It takes the data frame as the input and the return type is a new data frame containing the elements that are in data frame1 as well as in data frame2.
- This transformation takes out all the elements whether its duplicate or not and appends them making them into a single data frame for further operational purposes.
- We can also apply the union operation to more than one data frame in a spark application. The physical plan for union shows that the shuffle stage is represented by the Exchange node from all the columns involved in the union and is applied to each and every element in the data Frame.
Examples of PySpark Union
Let us see some Example of how the PYSPARK UNION function works:
Example #1
Let’s start by creating a simple Data Frame over we want to use the Filter Operation.
Code:
Creation of DataFrame:
a= spark.createDataFrame(["SAM","JOHN","AND","ROBIN","ANAND"], "string").toDF("Name")Lets create one more Data Frame b over union operation to be performed on.
b= spark.createDataFrame(["DAN","JACK","AND"], "string").toDF("Name")Let’s start a basic union operation.
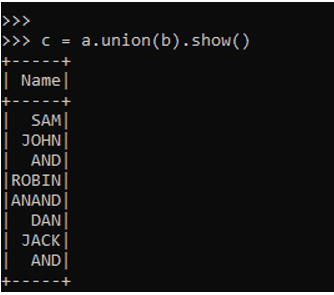
c = a.union(b).show()The output will append both the data frames together and the result will have both the data Frames together.
Output:
Example #2
The union operations deal with all the data and doesn’t handle the duplicate data in it. To remove the duplicates from the data frame we need to do the distinct operation from the data frame. The Distinct or Drop Duplicate operation is used to remove the duplicates from the Data Frame.
Code:
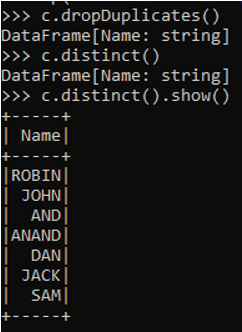
c.dropDuplicates()
c.distinct()
c.distinct().show()Output:
Example #3
We can also perform multiple union operations over the PySpark Data Frame. The same union operation can be applied to all the data frames.
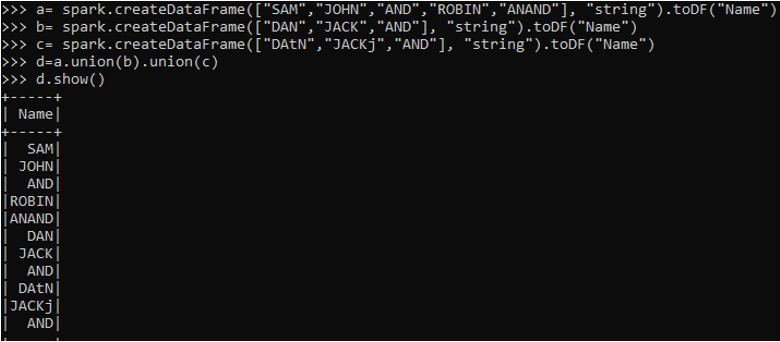
a= spark.createDataFrame(["SAM","JOHN","AND","ROBIN","ANAND"], "string").toDF("Name")
b= spark.createDataFrame(["DAN","JACK","AND"], "string").toDF("Name")
c= spark.createDataFrame(["DAtN","JACKj","AND"], "string").toDF("Name")
d=a.union(b).union(c)
d.show()This will union all three Data frames.
Output:
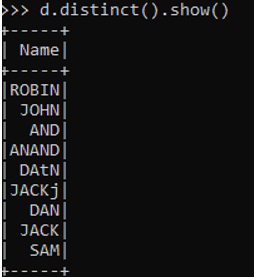
d.distinct().show()The distinct will remove all the duplicates from the Data Frame created.
Example #4
The same union operation can be done with Data Frame with Integer type as the data type also.
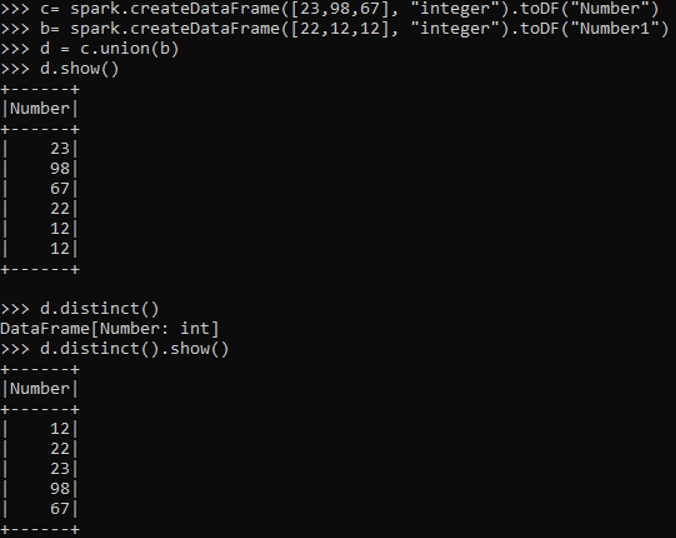
c= spark.createDataFrame([23,98,67], "integer").toDF("Number")
b= spark.createDataFrame([22,12,12], "integer").toDF("Number1")
d = c.union(b)
d.show()This is of type Integer and post applying union will append all the data frames together.
d.distinct()
d.distinct().show()Output:
Example #5
Let us see some more examples over the union operation on data frame.
data1 = [{'Name':'Jhon','ID':2,'Add':'USA'},{'Name':'Joe','ID':3,'Add':'MX'},{'Name':'Tina','ID':4,'Add':'IND'}] data2 = [{'Name':'Jhon','ID':21,'Add':'USA'},{'Name':'Joes','ID':31,'Add':'MX'},{'Name':'Tina','ID':43,'Add':'IND'}] rd1 = sc.parallelize(data1)
rd2 = sc.parallelize(data2)
df1 = spark.createDataFrame(rd1)
df2 = spark.createDataFrame(rd2)
df1.show()Let perform union operation over the Data Frame and analyze.
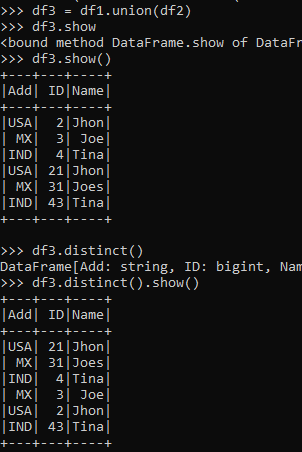
df3 = df1.union(df2)
df3.show()
df3.distinct()
df3.distinct().show()Output: