PySpark Select Columns is a function used in PySpark to select columns in a PySpark Data Frame. It could be the whole column, single as well as multiple columns of a Data Frame. It is a transformation function that returns a new data frame every time with the condition inside it. We can also select all the columns from a list using the select function.
The select column is a very important functionality on a PySpark data frame which gives us the privilege of selecting the columns of our need in a PySpark making the data more defined and usable. With the select column, we can have the option of selecting the column we need and leaving the rest of the columns that are not needed in a PySpark data frame.
Syntax:
The syntax for PySpark Select Columns function is:
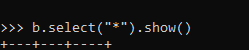
b.select("*").show()b: The data frame to be used for operation.
- select(): The select operation to be used for selecting columns.
- show(): The operation used to show the Data Frame.
Screenshot:
Working of Select Column in PySpark
Let us see somehow the SELECT COLUMN function works in PySpark:
The SELECT function selects the column from the database in a PySpark Data Frame. It is a transformation function that takes up the existing data frame and selects the data frame that is needed further. The selected data frame is put up into a new data frame. This method looks up for the argument that is given selecting the column, creates a new data frame, and returns back to users for operation.
A query plan is generated that retrieves the particular column that is given as the argument within the select statement. The plan is executed in an optimized way that returns the result set giving the values out of it.
The * keyword specifies to return all the columns in a PYSPARK Data Frame.
The select statement here in the Data Frame model is similar to that of the SQL Model where we write down the queries using the select statement to select a group of records from a Data Frame.
We can select a single column, multiple columns, a column directed by Index, or nested columns from a PySpark Data Frame using the select column. Let’s check these with some coding examples.
Let us see some Examples of How PySpark Select Columns function works:
Let’s start by creating simple data in PySpark.
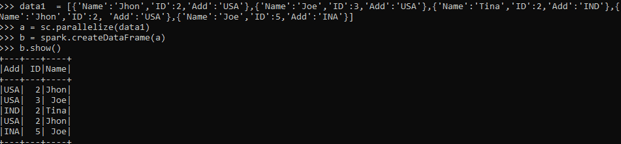
data1 = [{'Name':'Jhon','ID':2,'Add':'USA'},{'Name':'Joe','ID':3,'Add':'USA'},{'Name':'Tina','ID':2,'Add':'IND'},{'Name':'Jhon','ID':2, 'Add':'USA'},{'Name':'Joe','ID':5,'Add':'INA'}]A sample data is created with Name , ID and ADD as the field.
a = sc.parallelize(data1)RDD is created using sc.parallelize.
we will discuss sc.parallelize in next tutorial.
b = spark.createDataFrame(a)
b.show()Created Data Frame using Spark.createDataFrame.
Screenshot:
To retrieve all the columns of a Data Frame.
Code:
b.select("*").show()This selects all the columns of a Data Frame in PySpark.
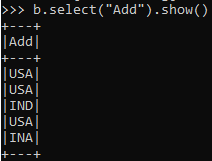
To SELECT particular columns using the select option in PySpark Data Frame.
b.select("Add").show()Output:
Screenshot:
Code for Other Columns:
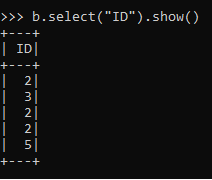
b.select("ID").show()This selects the ID Column From the DATA FRAME.
The same can be done by aliasing the Data Frame. Using the DataFrame.ColumnName.
b.select(b.ID).show()The output will be the same as the one selected.
Output:
We can also loop the variable in the Data Frame and can select the PySpark Data Frame with it.
b.select([col for col in b.columns]).show()The same will iterate through all the columns in a Data Frame and selects the value out of it.
We can select elements based on index also. The indexed method can be done from the select statement.
Code:
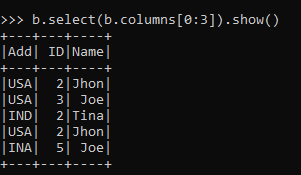
b.select(b.columns[0:3]).show()This will select the indexed column from 0 to 3 and show the result.
Output:
These are some of the Examples of SELECT COLUMN Function in PySpark.
Note:
- PySpark select is a Transformation operation.
- It selects the data Frame needed for the analysis of data.
- The result is stored in a new Data Frame.
- We can select single, multiple, all columns from a PySpark Data Frame.
- The selected data can be used further for modeling of data over PySpark Operation.
- We can also select the data using the col operation which selects the column needed for PySpark Data Frame.

