Introduction to PySpark Repartition
PySpark repartition is a concept in PySpark that is used to increase or decrease the partitions used for processing the RDD/Data Frame in the PySpark model. The PySpark model is based on the Partition of data and processing the data among that partition, the repartition concepts the data that is used to increase or decrease these particular partitions based on the requirement and data size.
A full shuffle model is applied while doing repartition which redistributes the data by shuffling all the data in it. This full shuffling of data sometimes makes the operation costs as data is transferred through the entire network.
In this article, we will try to analyze the various ways of using the Repartition operation in PySpark.
Let us try to see about PySpark REPARTITIONS in some more details
Syntax of PySpark Repartition
The syntax is:
c = b.rdd.repartition(5)
c.getNumPartitions()B:- The data frame to be used.
C:- The new repartitioned converted RDD. GetNumPartitions is used to check the new partition used.
Screenshot:

Working of PySpark Repartition
The PySpark model is purely based on a partition of data that distributes the data in partition and data model processing is done over that model. The repartition of data allows the control of the partition of data over which the data processing needs to be done.
The repartition redistributes the data by allowing full shuffling of data. We can increase or decrease the number of partitions using the concept of Repartition. There is a by default shuffle partition that allows the shuffling of data, this property is used for the repartition of data.
It controls the movement of data over spark cluster, A Repartition by Expression to the logical spark plan is added while using the repartition which is post-converted in the spark plan that repartitions the data eventually. If only one parameter is passed the data is randomly distributed.
This is how REPARTITION is used in PySpark.
Example of PySpark Repartition
Let us see some examples of how the PySpark Repartition function works. Let’s start by creating a PySpark Data Frame.
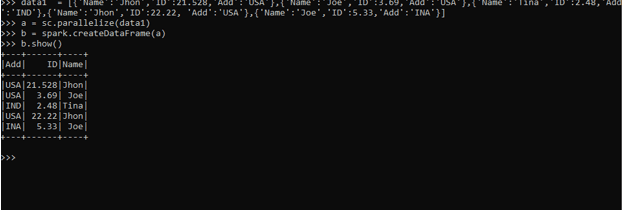
A data frame of Name with the concerned ID and Add is taken for consideration and a data frame is made upon that.
Code:
data1 = [{'Name':'Jhon','ID':21.528,'Add':'USA'},{'Name':'Joe','ID':3.69,'Add':'USA'},{'Name':'Tina','ID':2.48,'Add':'IND'},{'Name':'Jhon','ID':22.22, 'Add':'USA'},{'Name':'Joe','ID':5.33,'Add':'INA'}]The sc.parallelize method is used for creating an RDD from the data.
a = sc.parallelize(data1)The spark.createDataFrame method is then used for the creation of DataFrame.
b = spark.createDataFrame(a)Screenshot:
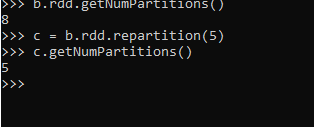
b.rdd.getNumPartitions()
8This is the default partition that is used. This distributes the data accordingly into 8 partitions.
We will repartition the data and the data is then shuffled into a new partition, The no can be less or more depending on the size of data and business use case needed.
c = b.rdd.repartition(5)
c.getNumPartitions()
5This repartitions the data into 5 partitions.
Screenshot:
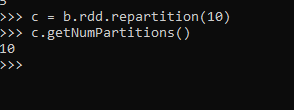
We can also increase the partition based on our requirement there is no limit to the partition of the data as this is an all full shuffle of the data model.
c = b.rdd.repartition(10)
c.getNumPartitions()
10This repartitions the data to a new partition number that is more than the default one. i.e 8.
Screenshot:
The same repartition concepts can be applied to RDD also by using the sc.parallelize function in PySpark and using the repartition concept over the same.
Creation of RDD using the sc.parallelize method.
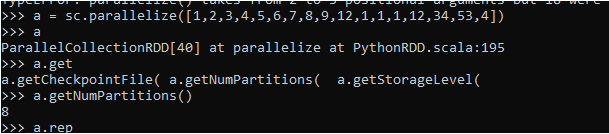
a = sc.parallelize([1,2,3,4,5,6,7,8,9,12,1,1,1,12,34,53,4])
a
ParallelCollectionRDD[40] at parallelize at PythonRDD.scala:195The default Partition that Spark uses.
a.getNumPartitions()
8The Repartition of data redefines the partition to be 2 .
c=a.repartition(2)
c
MapPartitionsRDD[50] at coalesce at NativeMethodAccessorImpl.java:0
c.getNumPartitions()
2Here we are increasing the partition to 10 which is greater than the normally defined partition.
d = a.repartition(10)
d
MapPartitionsRDD[55] at coalesce at NativeMethodAccessorImpl.java:0
d.get
d.getCheckpointFile( d.getNumPartitions( d.getStorageLevel(
d.getNumPartitions()
10This defines the working of repartition of data where we can increase or decrease the partition based on data and requirements. Sometimes repartition of data makes the processing of data easier and faster but as there is a full shuffling it makes the operation costs.
Screenshot:
Note
1. PySpark Repartition is used to increase or decrease the number of partitions in PySpark.
2. PySpark Repartition provides a full shuffling of data.
3. PySpark Repartition is an expensive operation since the partitioned data is restructured using the shuffling operation.
4. PySpark Repartition can be used to organize the data accordingly.

