Question #26
You have a dataset that contains information about taxi journeys that occurred during a given period.
You need to train a model to predict the fare of a taxi journey.
What should you use as a feature?
- A. the number of taxi journeys in the dataset
- B. the trip distance of individual taxi journeys
- C. the fare of individual taxi journeys
- D. the trip ID of individual taxi journeys
Correct Answer: B
The label is the column you want to predict. The identified Featuresare the inputs you give the model to predict the Label.
Example:
The provided data set contains the following columns:
vendor_id: The ID of the taxi vendor is a feature.
rate_code: The rate type of the taxi trip is a feature.
passenger_count: The number of passengers on the trip is a feature. trip_time_in_secs: The amount of time the trip took. You want to predict the fare of the trip before the trip is completed. At that moment, you don’t know how long the trip would take. Thus, the trip time is not a feature and you’ll exclude this column from the model. trip_distance: The distance of the trip is a feature. payment_type: The payment method (cash or credit card) is a feature. fare_amount: The total taxi fare paid is the label.
Reference:
https://docs.microsoft.com/en-us/dotnet/machine-learning/tutorials/predict-prices
Question #27
You need to predict the sea level in meters for the next 10 years.
Which type of machine learning should you use?
- A. classification
- B. regression
- C. clustering
Correct Answer: B
In the most basic sense, regression refers to prediction of a numeric target.
Linear regression attempts to establish a linear relationship between one or more independent variables and a numeric outcome, or dependent variable.
You use this module to define a linear regression method, and then train a model using a labeled dataset. The trained model can then be used to make predictions.
Reference:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/linear-regression
Question #28
HOTSPOT –
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Hot Area:

Correct Answer:

Box 1: Yes –
Automated machine learning, also referred to as automated ML or AutoML, is the process of automating the time consuming, iterative tasks of machine learning model development. It allows data scientists, analysts, and developers to build ML models with high scale, efficiency, and productivity all while sustaining model quality.
Box 2: No –
Box 3: Yes –
During training, Azure Machine Learning creates a number of pipelines in parallel that try different algorithms and parameters for you. The service iterates through
ML algorithms paired with feature selections, where each iteration produces a model with a training score. The higher the score, the better the model is considered to “fit” your data. It will stop once it hits the exit criteria defined in the experiment.
Box 4: No –
Apply automated ML when you want Azure Machine Learning to train and tune a model for you using the target metric you specify.
The label is the column you want to predict.
Reference:
https://azure.microsoft.com/en-us/services/machine-learning/automatedml/#features
Question #29
HOTSPOT –
To complete the sentence, select the appropriate option in the answer area.
Hot Area:

Hide Solution Discussion 19
Correct Answer: 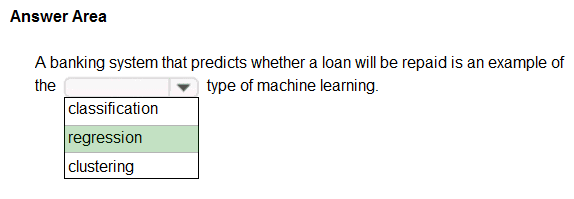
In the most basic sense, regression refers to prediction of a numeric target.
Example: Regression Model: A Boosted Decision Tree algorithm was used to create and train the model for predicting the repayment rate.
Reference:
https://gallery.azure.ai/Experiment/Student-Loan-Repayment-Rate-Prediction
Question #30
HOTSPOT –
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Hot Area:

Correct Answer: 
Box 1: Yes –
In machine learning, if you have labeled data, that means your data is marked up, or annotated, to show the target, which is the answer you want your machine learning model to predict.
In general, data labeling can refer to tasks that include data tagging, annotation, classification, moderation, transcription, or processing.
Box 2: No –
Box 3: No –
Accuracy is simply the proportion of correctly classified instances. It is usually the first metric you look at when evaluating a classifier. However, when the test data is unbalanced (where most of the instances belong to one of the classes), or you are more interested in the performance on either one of the classes, accuracy doesn’t really capture the effectiveness of a classifier.
Reference:
https://docs.microsoft.com/en-us/azure/machine-learning/studio/evaluate-model-performance




good