Question #11
Which service should you use to extract text, key/value pairs, and table data automatically from scanned documents?
- A. Form Recognizer
- B. Text Analytics
- C. Ink Recognizer
- D. Custom Vision
Correct Answer: A
Accelerate your business processes by automating information extraction. Form Recognizer applies advanced machine learning to accurately extract text, key/ value pairs, and tables from documents. With just a few samples, Form Recognizer tailors its understanding to your documents, both on-premises and in the cloud. Turn forms into usable data at a fraction of the time and cost, so you can focus more time acting on the information rather than compiling it.
Reference:
https://azure.microsoft.com/en-us/services/cognitive-services/form-recognizer/
Question #12
HOTSPOT –
To complete the sentence, select the appropriate option in the answer area.
Hot Area:

Correct Answer: 
Accelerate your business processes by automating information extraction. Form Recognizer applies advanced machine learning to accurately extract text, key/ value pairs, and tables from documents. With just a few samples, Form Recognizer tailors its understanding to your documents, both on-premises and in the cloud. Turn forms into usable data at a fraction of the time and cost, so you can focus more time acting on the information rather than compiling it.
Reference:
https://azure.microsoft.com/en-us/services/cognitive-services/form-recognizer/
Question #13
You use Azure Machine Learning designer to publish an inference pipeline.
Which two parameters should you use to consume the pipeline? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- A. the model name
- B. the training endpoint
- C. the authentication key
- D. the REST endpoint
Correct Answer: AD
A: The trained model is stored as a Dataset module in the module palette. You can find it under My Datasets.
Azure Machine Learning designer lets you visually connect datasets and modules on an interactive canvas to create machine learning models.
D: You can consume a published pipeline in the Published pipelines page. Select a published pipeline and find the REST endpoint of it.
Reference:
https://docs.microsoft.com/en-us/azure/machine-learning/how-to-run-batch-predictions-designer https://docs.microsoft.com/en-us/azure/machine-learning/concept-designer
Question #14
HOTSPOT –
To complete the sentence, select the appropriate option in the answer area.
Hot Area:
Correct Answer: 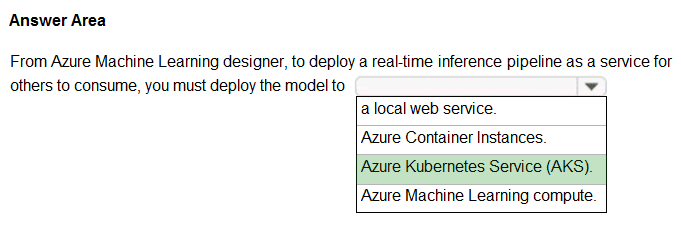
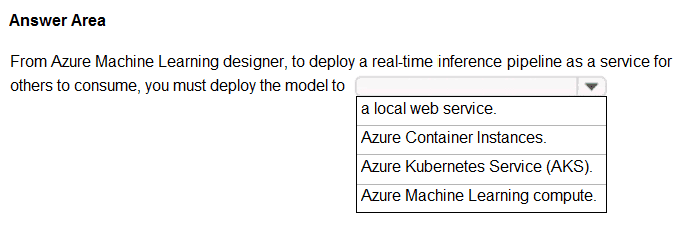
To perform real-time inferencing, you must deploy a pipeline as a real-time endpoint.
Real-time endpoints must be deployed to an Azure Kubernetes Service cluster.
Reference:
https://docs.microsoft.com/en-us/azure/machine-learning/concept-designer#deploy
Question #15
HOTSPOT –
To complete the sentence, select the appropriate option in the answer area.
Hot Area:

Correct Answer:

In the most basic sense, regression refers to prediction of a numeric target.
Linear regression attempts to establish a linear relationship between one or more independent variables and a numeric outcome, or dependent variable.
You use this module to define a linear regression method, and then train a model using a labeled dataset. The trained model can then be used to make predictions.
Incorrect Answers:
✑ Classification is a machine learning method that uses data to determine the category, type, or class of an item or row of data.
✑ Clustering, in machine learning, is a method of grouping data points into similar clusters. It is also called segmentation.
Over the years, many clustering algorithms have been developed. Almost all clustering algorithms use the features of individual items to find similar items. For example, you might apply clustering to find similar people by demographics. You might use clustering with text analysis to group sentences with similar topics or sentiment.
Reference:
https://docs.microsoft.com/en-us/azure/machine-learning/algorithm-module-reference/linear-regression https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/machine-learning-initialize-model-clustering




good