This tutorial will explain Advanced Guide to AWS DeepRacer with All Tips and Hacks to Win the Race and we will learn detailed steps for creating a vehicle model, creating a model, how we can tweak our reward function to generate faster lap times, training a model, evaluating a model and then submitting it to race. We will discuss other methods associated with the DeepRacer which can help in developing a faster racecar.
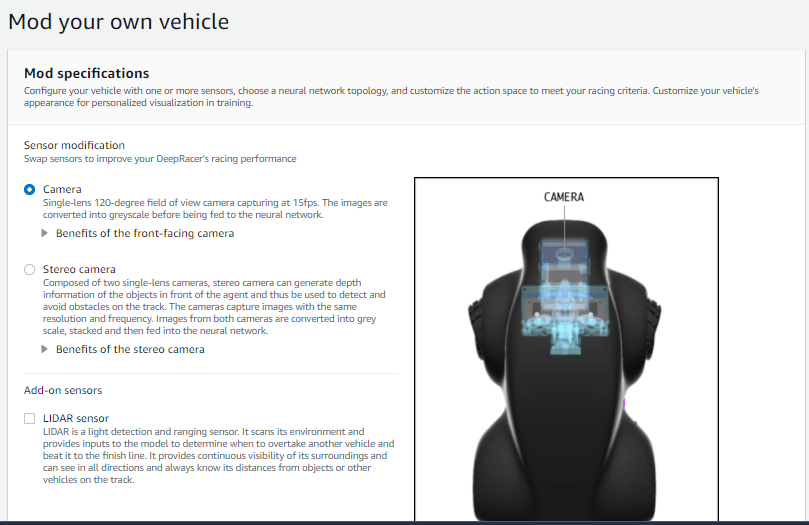
1. Create Your Vehicle Model
- Go to AWS DeepRacer > Your Garage
- Click on Build New Vehicle with the below-mentioned settings.

2. Create Your Model
- Go to AWS DeepRacer > Your Models
- Click on Create Model
Reward Function
After creating a Car Model you need a Reward Function and this this will be the most important part. A reward function describes immediate feedback (as a score for reward or penalty) when the vehicle takes an action to move from a given position on the track to a new position. Its purpose is to encourage the vehicle to make moves along the track to reach its destination quickly. The model training process will attempt to find a policy which maximizes the average total reward the vehicle experiences.
At myTechMint we have a dedicated course on Python for Data Scientists which we would recommend you to go through.
Reward Function Inputs
The AWS DeepRacer reward function takes a dictionary object as the input.
def reward_function(params) :
reward = ...
return float(reward) The params dictionary object contains the following key-value pairs:
{
"all_wheels_on_track": Boolean, # flag to indicate if the agent is on the track
"x": float, # agent's x-coordinate in meters
"y": float, # agent's y-coordinate in meters
"closest_objects": [int, int], # zero-based indices of the two closest objects to the agent's current position of (x, y).
"closest_waypoints": [int, int], # indices of the two nearest waypoints.
"distance_from_center": float, # distance in meters from the track center
"is_crashed": Boolean, # Boolean flag to indicate whether the agent has crashed.
"is_left_of_center": Boolean, # Flag to indicate if the agent is on the left side to the track center or not.
"is_offtrack": Boolean, # Boolean flag to indicate whether the agent has gone off track.
"is_reversed": Boolean, # flag to indicate if the agent is driving clockwise (True) or counter clockwise (False).
"heading": float, # agent's yaw in degrees
"objects_distance": [float, ], # list of the objects' distances in meters between 0 and track_length in relation to the starting line.
"objects_heading": [float, ], # list of the objects' headings in degrees between -180 and 180.
"objects_left_of_center": [Boolean, ], # list of Boolean flags indicating whether elements' objects are left of the center (True) or not (False).
"objects_location": [(float, float),], # list of object locations [(x,y), ...].
"objects_speed": [float, ], # list of the objects' speeds in meters per second.
"progress": float, # percentage of track completed
"speed": float, # agent's speed in meters per second (m/s)
"steering_angle": float, # agent's steering angle in degrees
"steps": int, # number steps completed
"track_length": float, # track length in meters.
"track_width": float, # width of the track
"waypoints": [(float, float), ] # list of (x,y) as milestones along the track center
} A more detailed technical reference of the input parameters is as follows
Input Parameter:
all_wheels_on_track
Type: Boolean
Range: (True:False)
A Boolean flag to indicate whether the agent is on-track or off-track. It’s off-track (False) if any of its wheels are outside of the track borders. It’s on-track (True) if all of the wheels are inside the two track borders.
The following illustration shows that the agent is on-track.

The following illustration shows that the agent is off-track.

Example: A reward function using the all_wheels_on_track parameter
define reward_function(params):
#############################################################################
'''
Example of using all_wheels_on_track and speed
'''
# Read input variables
all_wheels_on_track = params['all_wheels_on_track']
speed = params['speed']
# Set the speed threshold based your action space
SPEED_THRESHOLD = 1.0
if not all_wheels_on_track:
# Penalize if the car goes off track
reward = 1e-3
elif speed < SPEED_THRESHOLD:
# Penalize if the car goes too slow
reward = 0.5
else:
# High reward if the car stays on track and goes fast
reward = 1.0
return reward` Input Paramaters:
waypoints
Type: list of [float, float]
Range: [[xw,xw,0,yw,yw,0] … [xw,Max−1xw,Max−1, yw,Max−1yw,Max−1]]
An ordered list of track-dependent Max milestones along the track center. Each milestone is described by a coordinate of (xw,ixw,i, yw,iyw,i). For a looped track, the first and last waypoints are the same. For a straight or other non-looped track, the first and last waypoints are different.

Example: A reward function using the waypoints parameter was used in the closest_waypoints example below
Input Parameter:
closest_waypoints
Type: [int, int]
Range: [(0:Max-1),(1:Max-1)]
The zero-based indices of the two neighboring waypoints closest to the agent’s current position of (x, y). The distance is measured by the Euclidean distance from the center of the agent. The first element refers to the closest waypoint behind the agent and the second element refers the closest waypoint in front of the agent. Max is the length of the waypoints list. In the illustration shown in waypoints, the closest_waypoints would be [16, 17].
Example: A reward function using the closest_waypoints parameter.
The following example reward function demonstrates how to use waypoints and closest_waypoints as well as heading to calculate immediate rewards.
def reward_function(params):
###############################################################################
'''
Example of using waypoints and heading to make the car in the right direction
'''
import math
# Read input variables
waypoints = params['waypoints']
closest_waypoints = params['closest_waypoints']
heading = params['heading']
# Initialize the reward with typical value
reward = 1.0
# Calculate the direction of the center line based on the closest waypoints
next_point = waypoints[closest_waypoints[1]]
prev_point = waypoints[closest_waypoints[]]
# Calculate the direction in radius, arctan2(dy, dx), the result is (-pi, pi) in radians
track_direction = math.atan2(next_point[1] - prev_point[1], next_point[] - prev_point[])
# Convert to degree
track_direction = math.degrees(track_direction)
# Calculate the difference between the track direction and the heading direction of the car
direction_diff = abs(track_direction - heading)
if direction_diff > 180:
direction_diff = 360 - direction_diff
# Penalize the reward if the difference is too large
DIRECTION_THRESHOLD = 10.0
if direction_diff > DIRECTION_THRESHOLD:
reward *= 0.5
return reward Input Parameters:
heading
Type: float
Range: -180:+180
Heading direction, in degrees, of the agent with respect to the x-axis of the coordinate system.

Example: A reward function using the heading parameter can be seen in the closest_waypoints example above
Input Parameter:
closest_objects
Type: [int, int]
Range: [(0:len(object_locations)-1), (0:len(object_locations)-1]
The zero-based indices of the two closest objects to the agent’s current position of (x, y). The first index refers to the closest object behind the agent, and the second index refers to the closest object in front of the agent. If there is only one object, both indices are 0.
[box type=”warning” align=”” class=”” width=””]Note: This is primarily used for the object detection race in the AWS DeepRacer. For time trial race this can be ignored.[/box]
Input Parameter:
distance_from_center
Type: float
Range: 0:~track_width/2
Displacement, in meters, between the agent center and the track center. The observable maximum displacement occurs when any of the agent’s wheels are outside a track border and, depending on the width of the track border, can be slightly smaller or larger than half the track_width.

Example: A reward function using the distance_from_center parameter
def reward_function(params):
#################################################################################
'''
Example of using distance from the center
'''
# Read input variable
track_width = params['track_width']
distance_from_center = params['distance_from_center']
# Penalize if the car is too far away from the center
marker_1 = 0.1 * track_width
marker_2 = 0.5 * track_width
if distance_from_center <= marker_1:
reward = 1.0
elif distance_from_center <= marker_2:
reward = 0.5
else:
reward = 1e-3 # likely crashed/ close to off track
return reward Input Paramater:
is_crashed
Type: Boolean
Range: (True:False)
A Boolean flag to indicate whether the agent has crashed into another object (True) or not (False) as a termination status.
Input Paramater:
is_left_of_center
Type: Boolean
Range: (True : False)
A Boolean flag to indicate if the agent is on the left side to the track center (True) or on the right side (False).
Input Paramater:
is_offtrack
Type: Boolean
Range: (True:False)
A Boolean flag to indicate whether the agent has off track (True) or not (False) as a termination status.
Input Paramater:
is_reversed
Type: Boolean
Range: (True:False)
A Boolean flag to indicate if the agent is driving on clock-wise (True) or counter clock-wise (False).
It’s used when you enable direction change for each episode. An episode is a period in which the vehicle starts from a given starting point and ends up completing the track or going off the track.
Input Paramater:
objects_distance
Type: [float, … ]
Range: [(0:track_length), … ]
A list of the distances between objects in the environment in relation to the starting line. The ithith element measures the distance in meters between the ithith object and the starting line along the track center line.
To index the distance between a single object and the agent, use:
abs(params["objects_distance"][index] - (params["progress"]/100.0)*params["track_length"])

- Note
abs | (var1) – (var2)| = how close the car is to an object, WHEN var1 = [“objects_distance”][index] and var2 = params[“progress”]*params[“track_length”]
To get an index of the closest object in front of the vehicle and the closest object behind the vehicle, use the “closest_objects” parameter.
- This is primarily used for the object detection race in the AWS DeepRacer. For time trial race this can be ignored.
Input Parameter:
objects_heading
Type: [float, … ]
Range: [(-180:180), … ]
List of the headings of objects in degrees. The high element measures the heading of the this object. For stationary objects, their headings are 0. For a bot vehicle, the corresponding element’s value is the vehicle’s heading angle.
Input Parameter:
objects_left_of_center
Type: [Boolean, … ]
Range: [True|False, … ]
List of Boolean flags. The high element value indicates whether this object is to the left (True) or right (False) side of the track center.
Input Parameter:
objects_location
Type: [(x,y), …]
Range: [(0:N,0:N), …]
List of all object locations, each location is a tuple of (x, y).
The size of the list equals the number of objects on the track. Note the object could be the stationary obstacles, moving bot vehicles.
Input Parameter:
objects_speed
Type: [float, … ]
Range: [(0:12.0), … ]
List of speeds (meters per second) for the objects on the track. For stationary objects, their speeds are 0. For a bot vehicle, the value is the speed you set in training.
Input Parameter:
progress
Type: float
Range: 0:100
Percentage of track completed.
Example: A reward function using the progress parameter is shared below in the example of the steps
Input Parameters:
speed
Type: float
Range: 0.0:5.0
The observed speed of the agent, in meters per second (m/s)

Example: A reward function using the speed parameter was the initial all_wheels_on_track example
Input Parameters:
steering_angle
Type: float
Range: -30:30
Steering angle, in degrees, of the front wheels from the center line of the agent. The negative sign (-) means steering to the right and the positive (+) sign means steering to the left. The agent center line is not necessarily parallel with the track center line as is shown in the following illustration.

Example: A reward function using the steering_angle parameter
def reward_function(params):
'''
Example of using steering angle
'''
# Read input variable
steering = abs(params['steering_angle']) # We don't care whether it is left or right steering
# Initialize the reward with typical value
reward = 1.0
# Penalize if car steer too much to prevent zigzag
STEERING_THRESHOLD = 20.0
if steering > ABS_STEERING_THRESHOLD:
reward *= 0.8
return reward Input Parameter:
steps
Type: int
Range: 0:Nstep
The number of steps completed. A step corresponds to an action taken by the agent following the current policy.
Example: A reward function using the steps parameter
def reward_function(params):
#############################################################################
'''
Example of using steps and progress
'''
# Read input variable
steps = params['steps']
progress = params['progress']
# Total num of steps we want the car to finish the lap, it will vary depends on the track length
TOTAL_NUM_STEPS = 300
# Initialize the reward with typical value
reward = 1.0
# Give additional reward if the car pass every 100 steps faster than expected
if (steps % 100) == and progress > (steps / TOTAL_NUM_STEPS) * 100 :
reward += 10.0
return reward Input Parameters:
track_length
Type: float
Range: [0:Lmax]
The track length in meters. Lmax is track-dependent.
Input Parameter:
track_width
Type: float
Range: 0:Dtrack
Track width in meters.

Example: A reward function using the track_width parameter
def reward_function(params):
#############################################################################
'''
Example of using track width
'''
# Read input variable
track_width = params['track_width']
distance_from_center = params['distance_from_center']
# Calculate the distance from each border
distance_from_border = 0.5 * track_width - distance_from_center
# Reward higher if the car stays inside the track borders
if distance_from_border >= 0.05:
reward *= 1.0
else:
reward = 1e-3 # Low reward if too close to the border or goes off the track
return reward Input Parameters:
x, y
Type: float
Range: 0:N
Location, in meters, of the agent center along the x and y axes, of the simulated environment containing the track. The origin is at the lower-left corner of the simulated environment.

AWS DeepRacer Reward Function Examples
The following lists some examples of the AWS DeepRacer reward functions
Example 1: Follow the Center Line in Time Trials
Example 2: Stay Inside the Two Borders in Time Trials
Example 3: Prevent Zig-Zag in Time Trials
Example 4: Stay On One Lane without Crashing into Stationary Obstacles or Moving Vehicles
Example 1: Follow the Center Line in Time Trials
This example determines how far away the agent is from the center line, and gives higher reward if it is closer to the center of the track, encouraging the agent to closely follow the center line.
def reward_function(params):
'''
Example of rewarding the agent to follow center line
'''
# Read input parameters
track_width = params['track_width']
distance_from_center = params['distance_from_center']
# Calculate 3 markers that are increasingly further away from the center line
marker_1 = 0.1 * track_width
marker_2 = 0.25 * track_width
marker_3 = 0.5 * track_width
# Give higher reward if the car is closer to center line and vice versa
if distance_from_center <= marker_1:
reward = 1
elif distance_from_center <= marker_2:
reward = 0.5
elif distance_from_center <= marker_3:
reward = 0.1
else:
reward = 1e-3 # likely crashed/ close to off track
return reward 
Example 2: Stay Inside the Two Borders in Time Trials
This example simply gives high rewards if the agent stays inside the borders, and let the agent figure out what is the best path to finish a lap. It is easy to program and understand, but likely takes longer to converge.
def reward_function(params):
'''
Example of rewarding the agent to stay inside the two borders of the track
'''
# Read input parameters
all_wheels_on_track = params['all_wheels_on_track']
distance_from_center = params['distance_from_center']
track_width = params['track_width']
# Give a very low reward by default
reward = 1e-3
# Give a high reward if no wheels go off the track and
# the car is somewhere in between the track borders
if all_wheels_on_track and (0.5*track_width - distance_from_center) >= 0.05:
reward = 1.0
# Always return a float value
return reward Example 3: Prevent Zig-Zag in Time Trials
This example incentivizes the agent to follow the center line but penalizes with lower reward if it steers too much, which helps prevent zig-zag behavior. The agent learns to drive smoothly in the simulator and likely keeps the same behavior when deployed in the physical vehicle.
def reward_function(params):
'''
Example of penalize steering, which helps mitigate zig-zag behaviors
'''
# Read input parameters
distance_from_center = params['distance_from_center']
track_width = params['track_width']
steering = abs(params['steering_angle']) # Only need the absolute steering angle
# Calculate 3 marks that are farther and father away from the center line
marker_1 = 0.1 * track_width
marker_2 = 0.25 * track_width
marker_3 = 0.5 * track_width
# Give higher reward if the car is closer to center line and vice versa
if distance_from_center <= marker_1:
reward = 1.0
elif distance_from_center <= marker_2:
reward = 0.5
elif distance_from_center <= marker_3:
reward = 0.1
else:
reward = 1e-3 # likely crashed/ close to off track
# Steering penality threshold, change the number based on your action space setting
ABS_STEERING_THRESHOLD = 15
# Penalize reward if the car is steering too much
if steering > ABS_STEERING_THRESHOLD:
reward *= 0.8
return float(reward) In general, you design your reward function to act like an incentive plan.
For example, to keep the agent staying as close to the center line as possible, the reward function could return a reward of 1.0 if the vehicle is within 3cm from the center, a reward of 0.5 if the agent is within 10cm and a reward of 0.001 (stands for zero for practical purposes) otherwise.
You can customize your reward function with relevant input parameters passed into the reward function. However, you should understand that if your reward function includes details specific to the training track (such as the shape of the track), your model might learn a policy which does not generalize to other tracks.
Note that the model training process will try to optimize average total reward. Without taking this into account, your model might learn a policy which maximizes time spent accumulating reward (for example, by driving slowly or zig-zagging).
Example 4: Stay On One Lane without Crashing into Stationary Obstacles or Moving Vehicles
This reward function rewards the agent to stay between the track borders and penalizes the agent for getting too close to the next object in the front.
The agent can move from lane to lane to avoid crashes.
The total reward is a weighted sum of the reward and penalty.
The example gives more weight to the penalty term to focus more on safety by avoiding crashes.
You can play with different averaging weights to train the agent with different driving behaviors and to achieve different driving performances.
[box type=”warning” align=”aligncenter” class=”” width=””]Note: This example is for the object avoidance race type and can be ignored for the time trial competition[/box]
def reward_function(params):
'''
Example of rewarding the agent to stay inside two borders
and penalizing getting too close to the objects in front
'''
all_wheels_on_track = params['all_wheels_on_track']
distance_from_center = params['distance_from_center']
track_width = params['track_width']
objects_distance = params['objects_distance']
_, next_object_index = params['closest_objects']
objects_left_of_center = params['objects_left_of_center']
is_left_of_center = params['is_left_of_center']
# Initialize reward with a small number but not zero
# because zero means off-track or crashed
reward = 1e-3
# Reward if the agent stays inside the two borders of the track
if all_wheels_on_track and (0.5 * track_width - distance_from_center) >= 0.05:
reward_lane = 1.0
else:
reward_lane = 1e-3
# Penalize if the agent is too close to the next object
reward_avoid = 1.0
# Distance to the next object
distance_closest_object = objects_distance[next_object_index]
# Decide if the agent and the next object is on the same lane
is_same_lane = objects_left_of_center[next_object_index] == is_left_of_center
if is_same_lane:
if 0.5 <= distance_closest_object < 0.8:
reward_avoid *= 0.5
elif 0.3 <= distance_closest_object < 0.5:
reward_avoid *= 0.2
elif distance_closest_object < 0.3:
reward_avoid = 1e-3 # Likely crashed
# Calculate reward by putting different weights on
# the two aspects above
reward += 1.0 * reward_lane + 4.0 * reward_avoid
return reward 
AWS DeepRacer Reward Function Examples – Advanced
Based on experiences of people at various different AWS DeepRacer events across the globe, we have collated a set of advanced Reward functions which could help you achieve faster times
PurePursuit
Source- Github- scottpletcher/deepracer
Based on an academic paper from 1992 by R. Craig Coulter titled “Implementation of the Pure Pursuit Tracking Algorithm”.
When we drive a real car, we don’t look out the side window and ensure we’re a distance from the side of the road rather, we identify a point down the road and use that to orient ourselves.
All the hyperparameters were set to default and the training period was for about 4 hours
Note: This function is not an exact replica of the one stated at the source as the parameter listing have changed over time.
def reward_function(params):
import math
reward = 1e-3
rabbit = [,]
pointing = [,]
# Read input variables
waypoints = params['waypoints']
closest_waypoints = params['closest_waypoints']
heading = params['heading']
x=params['x']
y=params['y']
# Reward when yaw (car_orientation) is pointed to the next waypoint IN FRONT.
# Find nearest waypoint coordinates
rabbit = waypoints[closest_waypoints[1]]
radius = math.hypot(x - rabbit[], y - rabbit[1])
pointing[] = x + (radius * math.cos(heading))
pointing[1] = y + (radius * math.sin(heading))
vector_delta = math.hypot(pointing[] - rabbit[], pointing[1] - rabbit[1])
# Max distance for pointing away will be the radius * 2
# Min distance means we are pointing directly at the next waypoint
# We can setup a reward that is a ratio to this max.
if vector_delta == :
reward += 1
else:
reward += ( 1 - ( vector_delta / (radius * 2)))
return reward SelfMotivator
[box type=”success” align=”aligncenter” class=”” width=””]With supervised learning, your model will only be as good as the ground truth you have to give it. With reinforcement learning, the model has the potential to become better than anything or anyone has ever done that thing.[/box]
Trust in the reinforcement learning process to figure out the best way around the track.
The author decided to create a simple function that simply motivated the model to stay on the track and get around in as few steps as possible.
Trained for about 3 hours
def reward_function(params):
if params["all_wheels_on_track"] and params["steps"] > :
reward = ((params["progress"] / params["steps"]) * 100) + (params["speed"]**2)
else:
reward = 0.01
return float(reward) beSharp
Source- beSharp
Selecting the top reward functions by the author.
import math
def reward_function(params):
track_width = params['track_width']
distance_from_center = params['distance_from_center']
steering = abs(params['steering_angle'])
direction_stearing=params['steering_angle']
speed = params['speed']
steps = params['steps']
progress = params['progress']
all_wheels_on_track = params['all_wheels_on_track']
ABS_STEERING_THRESHOLD = 15
SPEED_TRESHOLD = 5
TOTAL_NUM_STEPS = 85
# Read input variables
waypoints = params['waypoints']
closest_waypoints = params['closest_waypoints']
heading = params['heading']
reward = 1.0
if progress == 100:
reward += 100
# Calculate the direction of the center line based on the closest waypoints
next_point = waypoints[closest_waypoints[1]]
prev_point = waypoints[closest_waypoints[]]
# Calculate the direction in radius, arctan2(dy, dx), the result is (-pi, pi) in radians
track_direction = math.atan2(next_point[1] - prev_point[1], next_point[] - prev_point[])
# Convert to degree
track_direction = math.degrees(track_direction)
# Calculate the difference between the track direction and the heading direction of the car
direction_diff = abs(track_direction - heading)
# Penalize the reward if the difference is too large
DIRECTION_THRESHOLD = 10.0
malus=1
if direction_diff > DIRECTION_THRESHOLD:
malus=1-(direction_diff/50)
if malus< or malus>1:
malus =
reward *= malus
return reward Source- Sarah Lueck
Selecting the top reward functions by the author.
import math
def reward_function(params):
# Read input parameters
track_width = params['track_width']
distance_from_center = params['distance_from_center']
all_wheels_on_track = params['all_wheels_on_track']
is_left_of_center = params['is_left_of_center']
steering_angle = params['steering_angle']
speed = params['speed']
if is_left_of_center == True:
distance_from_center *= -1
# implementation of reward function for distance from center
reward = (1 / (math.sqrt(2 * math.pi * (track_width*2/15) ** 2)) * math.exp(-((
distance_from_center + track_width/20) ** 2 / (4 * track_width*2/15) ** 2))) *(track_width*1/3)
if not all_wheels_on_track:
reward = 1e-3
# implementation of reward function for steering angle
STEERING_THRESHOLD = 14.4
if abs(steering_angle) < STEERING_THRESHOLD:
steering_reward = math.sqrt(- (8 ** 2 + steering_angle ** 2) + math.sqrt(4 * 8 ** 2 * steering_angle ** 2 + (12 ** 2) ** 2) ) / 10
else:
steering_reward =
# aditional reward if the car is not steering too much
reward *= steering_reward
# reward for the car taking fast actions (speed is in m/s)
reward *= math.sin(speed/math.pi * 5/6)
# same reward for going slow with greater steering angle then going fast straight ahead
reward *= math.sin(0.4949 * (0.475 * (speed - 1.5241) + 0.5111 * steering_angle ** 2))
return float(reward) Hyperparameter Values
After creating a good Reward Funcation you will need Hyperparameters Values. It can be set while creating the Models to train. Below is the default Hyperparameters values, that you can set to trail your model.
| Hyperparameter | Value |
|---|---|
| Gradient Descent Batch Size | 64 |
| Entropy | 0.01 |
| Discount Factor | 0.999 |
| Loss Type | Huber |
| Learning Rate | 0.0003 |
| No# Experience Episodes between each policy-updating iteration | 20 |
| No# of Epochs | 10 |
[tie_index]Start Evaluation[/tie_index]
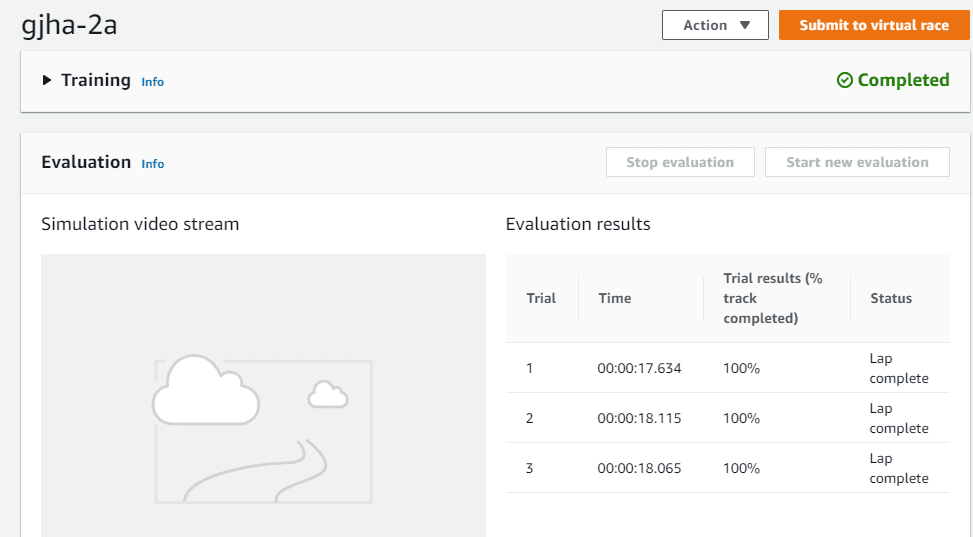
3. Start Evaluation
After successfully completing the training you can test your Model by Evaluating it in a Virtual Environment.
Below is the screenshot of the Evaluation Result.
[tie_index]Submit to Virtual Race[/tie_index]
4. Submit to Virtual Race
Now the last step is to submit your trained model for Race, by clicink on “Submit to Virtual Race” after completing the Evaluation.

[tie_index]Additional Information and Tips[/tie_index]
5. Additional Information and Tips
Convergence:
Convergence in Machine learning describes a set of weights during supervised training, as a model begins to find (converge on) the values needed to produce the correct (trained) response.
Action Space
For autonomous driving, the AWS DeepRacer vehicle receives input images streamed at 15 frames per second from the front camera. The raw input is downsized to 160×120 pixels in size and converted to grayscale images.
Responding to an input observation, the vehicle reacts with a well-defined action of specific speed and steering angle. The actions are converted to low-level motor controls. The possible actions a vehicle can take is defined by an action space of the dimensions in speed and steering angle. An action space can be discrete or continuous. AWS DeepRacer uses a discrete action space.
For a discrete action space of finite actions, the range is defined by the maximum speed and the absolute value of the maximum steering angles. The granularities define the number of speeds and steering angles the agent has.
Overfitting
Overfitting refers to a model that models the training data too well.
Log Analysis
One of the most involving aspect of learning with DeepRacer is observing the impact of changes to the training and identifying what can be improved to progress. Without the ability to see that training becomes walking in the dark and can be both frustrating and wasteful.
Log analysis lets you read the training, evaluation or submission logs, load them into data series formats and process them to provide data in form of tables or plots.
Waypoints
Map put your machine learning journey with waypoints
Variable future waypoints
Help your model keep its eye on the road with variable future waypoints.
Hyperparameters
Hyperparameters are variables to control your reinforcement learning training. They can be tuned to optimize the training time and your model performance.
The optimization technique used by AWS Deepracer is the PPO which stands for Proximal Policy Optimization.
Looking into the various hyper parameters:
1. Gradient descent batch size
The number of recent vehicle experiences sampled at random from an experience buffer and used for updating the underlying deep-learning neural network weights. Random sampling helps reduce correlations inherent in the input data. Use a larger batch size to promote more stable and smooth updates to the neural network weights, but be aware of the possibility that the training may be longer or slower.
The batch is a subset of an experience buffer that is composed of images captured by the camera mounted on the AWS DeepRacer vehicle and actions taken by the vehicle.
2. Number of epochs
The number of passes through the training data to update the neural network weights during gradient descent. The training data corresponds to random samples from the experience buffer. Use a larger number of epochs to promote more stable updates, but expect a slower training. When the batch size is small, you can use a smaller number of epochs.
3. Learning rate
During each update, a portion of the new weight can be from the gradient-descent (or ascent) contribution and the rest from the existing weight value. The learning rate controls how much a gradient-descent (or ascent) update contributes to the network weights. Use a higher learning rate to include more gradient-descent contributions for faster training, but be aware of the possibility that the expected reward may not converge if the learning rate is too large.
4. Entropy
The degree of uncertainty used to determine when to add randomness to the policy distribution. The added uncertainty helps the AWS DeepRacer vehicle explore the action space more broadly. A larger entropy value encourages the vehicle to explore the action space more thoroughly.
5. Discount factor
The discount factor determines how much of future rewards are discounted in calculating the reward at a given state as the averaged reward over all the future states. The discount factor of 0 means the current state is independent of future steps, whereas the discount factor 1 means that contributions from all of the future steps are included. With the discount factor of 0.9, the expected reward at a given step includes rewards from an order of 10 future steps. With the discount factor of 0.999, the expected reward includes rewards from an order of 1000 future steps.
6. Loss type
The type of the objective function to update the network weights. A good training algorithm should make incremental changes to the vehicle’s strategy so that it gradually transitions from taking random actions to taking strategic actions to increase reward. But if it makes too big a change then the training becomes unstable and the agent ends up not learning. The Huber and Mean squared error loss types behave similarly for small updates. But as the updates become larger, the Huber loss takes smaller increments compared to the Mean squared error loss. When you have convergence problems, use the Huber loss type. When convergence is good and you want to train faster, use the Mean squared error loss type.
7. Number of experience episodes between each policy-updating iteration
The size of the experience buffer used to draw training data from for learning policy network weights. An episode is a period in which the vehicle starts from a given starting point and ends up completing the track or going off the track. Different episodes can have different lengths. For simple reinforcement-learning problems, a small experience buffer may be sufficient and learning will be fast. For more complex problems which have more local maxima, a larger experience buffer is necessary to provide more uncorrelated data points. In this case, training will be slower but more stable. The recommended values are 10, 20, and 40.



May i have the waypoint map for re-invent: 2018 track? It would help if it simply visualize the map in number, e.g. starting point as 1-10, first left turn as 12-18, … finishing point as 68-70, etc. I try to search it in the map and it always tell me to generate the map by writing / running some code which i don’t know how to do. thank you.
only place to learn everything about aws deepracer in a single post. thank you so much.
Thank you – finally a clear , detailed guide.
thanks man .. concluded everything about aws deepracer.