Introduction to PySpark Explode
PySpark explode is an Explode function that is used in the PySpark data model to explode an array or map-related columns to row in PySpark. It explodes the columns and separates them not a new row in PySpark. It returns a new row for each element in an array or map.
It takes the column as the parameter and explodes up the column that can be further used for data modeling and data operation. The exploding function can be the developer the access the internal schema and progressively work on data that is nested. This explodes function usage avoids the loops and complex data-related queries needed.
In this article, we will try to analyze the various ways of using the Explode operation PySpark.
Let us try to see about Explode in some more detail.
The Syntax for PySpark Explode
The syntax for the Explode function is:-
from pyspark.sql.functions import explode
df2 = data_frame.select(data_frame.name,explode(data_frame.subjectandID))
df2.printSchema()
Df_inner:- The Final data frame formedScreenshot:

Working of Explode in PySpark with Example
Let us see some examples of how Explode operation works:-
Let’s start by creating simple data in PySpark.
data1 = [("Jhon",[["USA","MX","USW","UK"],["23","34","56"]]),("Joe",[["IND","AF","YR","QW"],["22","35","76"]]),("Juhi",[["USA","MX","USW","UK"],["13","64","59"]]),("Jhony",[["USSR","MXR","USA","UK"],["22","44","76"]])]The data is created with Array as an input into it.
data_frame = spark.createDataFrame(data=data1, schema = ['name','subjectandID'])Creation of Data Frame.
data_frame.printSchema()
data_frame.show(truncate=False)Output:
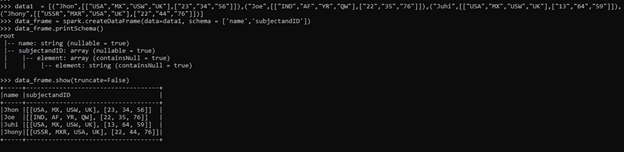
Here we can see that the column is of the type array which contains nested elements that can be further used for exploding.
Screenshot:
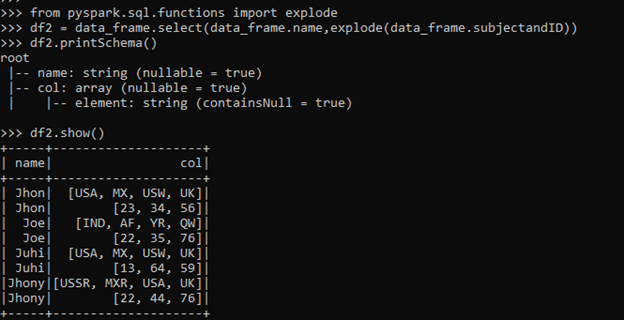
from pyspark.sql.functions import explode
Let us import the function using the explode function.
df2 = data_frame.select(data_frame.name,explode(data_frame.subjectandID))Let’s start by using the explode function that is to be used. The explode function uses the column name as the input and works on the columnar data.
df2.printSchema()
root
|-- name: string (nullable = true)
|-- col: array (nullable = true)
| |-- element: string (containsNull = true)The schema shows the col being exploded into rows and the analysis of output shows the column name to be changed into the row in PySpark. This makes the data access and processing easier and we can do data-related operations over there.
df2.show()The output breaks the array column into rows by which we can analyze the output being exploded based on the column values in PySpark.
The new column that is created while exploding an Array is the default column name containing all the elements of an Array exploded there.
The explode function can be used with Array as well the Map function also,
The exploded function creates up to two columns mainly the one for the key and the other for the value and elements split into rows.
Let us check this with some examples:-
data1 = [("Jhon",["USA","MX","USW","UK"],{'23':'USA','34':'IND','56':'RSA'}),("Joe",["IND","AF","YR","QW"],{'23':'USA','34':'IND','56':'RSA'}),("Juhi",["USA","MX","USW","UK"],{'23':'USA','34':'IND','56':'RSA'}),("Jhony",["USSR","MXR","USA","UK"],{'23':'USA','34':'IND','56':'RSA'})] data_frame = spark.createDataFrame(data=data1, schema = ['name','subjectandID'])
data_frame.printSchema()
root
|-- name: string (nullable = true)
|-- subjectandID: array (nullable = true)
| |-- element: string (containsNull = true)
|-- _3: map (nullable = true)
| |-- key: string
| |-- value: string (valueContainsNull = true)The data frame is created and mapped the function using key-value pair, now we will try to use the explode function by using the import and see how the Map function operation is exploded using this Explode function.
from pyspark.sql.functions import explode
df2 = data_frame.select(data_frame.name,explode(data_frame.subjectandID))
df2.printSchema()
root
|-- name: string (nullable = true)
|-- col: string (nullable = true)
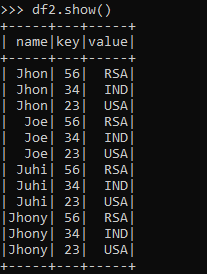
df2.show()The Output Example shows how the MAP KEY VALUE PAIRS are exploded using the Explode function.
Screenshot:-
Note
- Explode is a PySpark function used to works over columns in PySpark.
- Explode is used for the analysis of nested column data.
- PySpark Explode converts the Array of Array Columns to row.
- Explode can be flattened up post analysis using the flatten method.
- Explode returns type is generally a new row for each element given.

